Human-AI teams deliver the most accurate medical diagnoses

Our latest study published on PNAS demonstrates that the combination of human expertise with the capacity of state-of-the-art AI systems leads to significantly more accurate diagnoses. Specifically, we show that Large Language Models (LLMs) can effectively complement doctors in making diagnoses. However, neither humans nor LLMs are perfect. Still, they make different mistakes. This difference represents a previously untapped resource: combining human and AI diagnoses leads to the most accurate results.
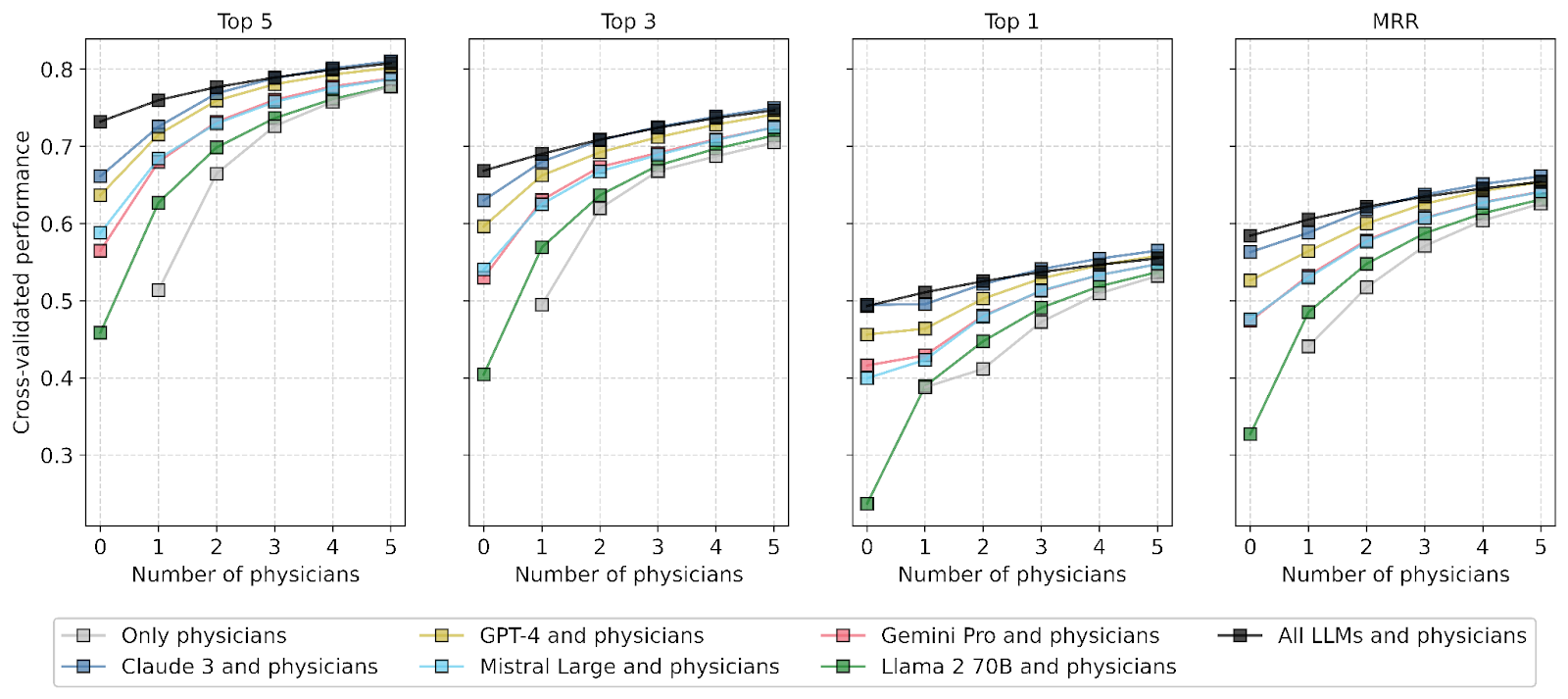
Performance of human-only ensembles and hybrid ensembles of humans and LLMs. Panels show performance for four outcome metrics. Top-n indicates the proportion of cases for which the correct diagnosis was among the n top-ranked diagnoses; MRR shows the mean reciprocal rank of correct diagnoses across cases. The individual performance of the five LLMs (and their combined performance in an all-LLMs ensemble) is shown as the Left-most square of each color in each panel. The x axis shows the number of humans added to individual LLMs or to an all-LLMs ensemble.
We used more than 2100 medical case vignettes—short descriptions of realistic patient complaints—together with their corresponding correct diagnoses, and compared the diagnoses made by medical professionals with those of five leading AI models. In the central experiment, various diagnostic teams were simulated: individuals, human groups, AI models, and mixed human-AI collectives. The study shows that combining multiple AI models improved diagnostic quality. On average, the AI ensemble outperformed 85% of human diagnosticians. However, there were numerous cases in which humans performed better. Most importantly, when the AI failed, humans often knew the correct diagnosis.
Hence, the combination of diagnoses provided by humans and LLMs led to a significant increase in accuracy. Even adding a single AI model to a group of human diagnosticians—or vice versa—noticeably improved the result. The most accurate outcomes came from collective decisions involving multiple humans and multiple AIs. When the AI failed in certain cases, a human professional could compensate for the mistake—and vice versa.
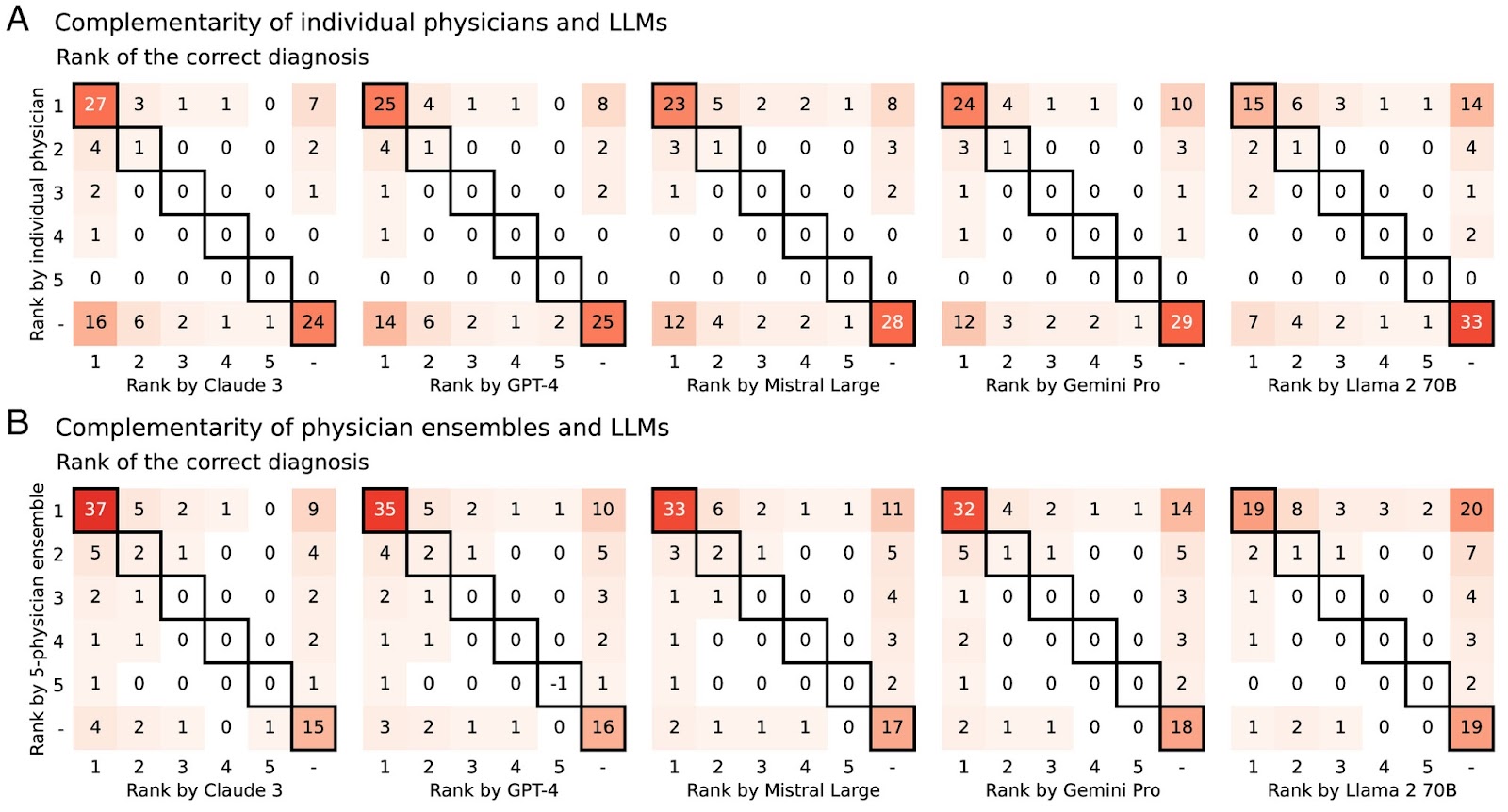
Complementarity of solutions between humans and LLMs. Each matrix represents the percentages of cases in which the correct diagnosis appeared in a given position (i.e., rank 1, 2, 3, 4, 5, or not ranked) within the differential provided by humans (rows) and LLMs (columns).The highlighted diagonal indicates cases where an LLM and the humans assigned the correct diagnosis the same rank. (A) Results for individual physicians. (B) Results for five-physician human-only ensembles. Graph extracted from the PNAS article.
The study offers important impulses for the development of future clinical decision-support systems based on the intelligent integration of human and machine intelligence. However, it is worth mentioning some limitations of the current study. First, only text-based case vignettes were examined—not actual patients in real clinical settings. Whether the results can be transferred directly to practice remains to be shown by follow-up studies. Likewise, the therapeutic consequences of the diagnoses were not considered—a correct diagnosis does not automatically mean optimal treatment. Another open question is how AI-based support systems will be accepted in practice by medical professionals and patients. The potential risks of bias and discrimination by AI—especially regarding ethnic, social, or gender differences—require further research.
More details:
“Human-AI Collectives Most Accurately Diagnose Clinical Vignettes”, N. Zöller, J. Berger, I. Lin, N. Fu, J. Komarneni, G. Barabucci, K. Laskowski, V. Shia, B. Harack, E. A. Chu, V. Trianni, R. H.J.M. Kurvers, S. M. Herzog, Human–AI collectives most accurately diagnose clinical vignettes, Proc. Natl. Acad. Sci. U.S.A. 122 (24) e2426153122 https://www.pnas.org/doi/10.1073/pnas.2426153122
News
A new video from our series explains how hybrid collective intelligence can be integrated with the Human…

Yet another video from our series explaining hybrid collective intelligence and its implications to…

In this new video, we explain what is hybrid collective intelligence—the improved ability to solve…

HACID partners from the Met Office are co-organising a session at the European Geosciences Union…

Our latest study published on PNAS demonstrates that the combination of human expertise with the capacity…
![]()
People ➞